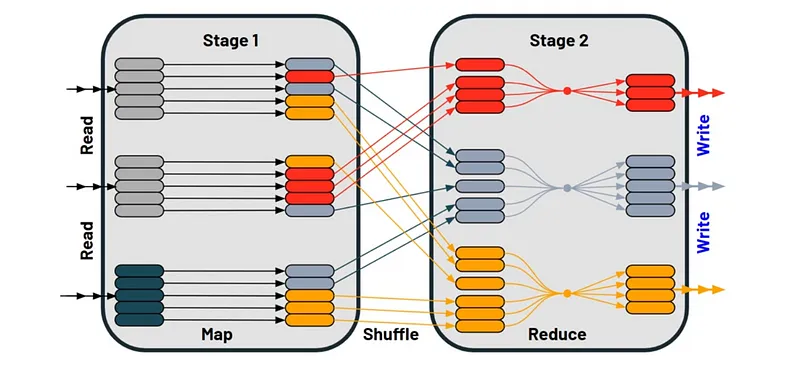
Shuffle
No contexto do Apache Spark, o termo "shuffle" se refere ao processo de redistribuição de dados entre partições. Esta etapa é crucial quando a reorganização ou o agrupamento de dados conforme chaves específicas é requerido, como nas operações de agrupamento ou "join". O shuffle é notório por ser uma das operações mais custosas em termos computacionais dentro do Spark, visto que demanda a transferência de dados entre diversos executores do cluster.
A ausência de um shuffle poderia resultar em partições com tamanhos desbalanceados, prejudicando o desempenho global da aplicação.
A ausência de um shuffle poderia resultar em partições com tamanhos desbalanceados, prejudicando o desempenho global da aplicação.
Como determinar a quantidade de Shuffles?
Para estimar a quantidade ótima de shuffles, sobretudo em relação ao parâmetro spark.sql.shuffle.partitions, os seguintes critérios devem ser considerados:
Para Datasets Grandes: Recomenda-se determinar o tamanho alvo da tarefa entre 100 MB e no máximo 200 MB por partição.
Fórmula Recomendada: Para definir spark.sql.shuffle.partitions utiliza-se: (tamanho de entrada do stage de shuffle / tamanho-alvo por partição) / total de núcleos) * total de núcleos.
Fórmula Recomendada: Para definir spark.sql.shuffle.partitions utiliza-se: (tamanho de entrada do stage de shuffle / tamanho-alvo por partição) / total de núcleos) * total de núcleos.
Consequências de um Shuffle Ineficiente
Um shuffle mal gerenciado pode levar a diversas consequências indesejáveis, incluindo:
Aumento no Tempo de Execução: Operações extensivas de shuffle podem ser muito demoradas, em especial se os dados estiverem distribuídos de maneira desequilibrada entre as partições.
Consumo Elevado de Recursos: Shuffles massivos podem demandar grande parte da CPU e memória, interferindo em outros jobs ou aplicações que estejam rodando no mesmo cluster.
Boas práticas
Para maximizar a eficiência do shuffle, algumas práticas são recomendadas:
Minimize Operações que Provocam Shuffle: Se possível, organize suas transformações de forma a reduzir as operações que induzam ao shuffle.
Ajuste o Tamanho das Partições: Adaptar o tamanho das partições pode ajudar a balancear a distribuição de tarefas entre os executores e reduzir o overhead associado ao shuffle.