O que é um RDD e um DataFrame Spark?
O que é um RDD?
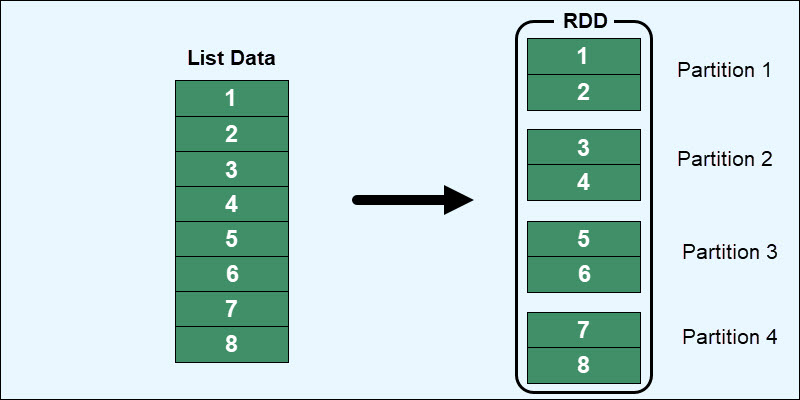
Um RDD (Resilient Distributed Dataset) é um conjunto imutável de itens de dados distribuídos por vários nós de um cluster, que pode ser manipulado através de APIs para realizar transformações e diversas outras ações. A estrutura do RDD foi projetada para ser:
- Resiliência: Como o nome sugere, RDDs são resilientes, o que significa que podem se recuperar automaticamente de falhas. A resiliência é alcançada através da retenção de informações sobre como um RDD pode ser reconstruído (normalmente um plano de linhagem) em caso de perda de dados.
- Distribuído: RDDs estão distribuídos por vários nós em um cluster, permitindo processamento paralelo.
- Dataset: Representa uma coleção (ou conjunto) de dados.
O que é um DataFrame Spark
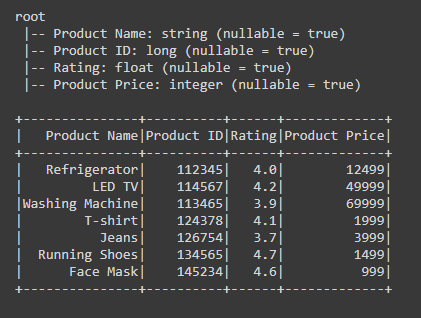
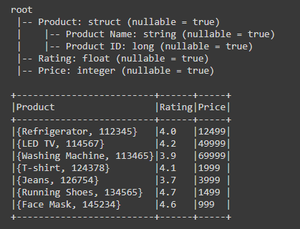
No Spark, DataFrames representam conjuntos de dados distribuídos organizados em linhas e colunas nomeadas. Semelhante às tabelas de bancos de dados tradicionais, cada coluna em um DataFrame tem um nome específico e um tipo de dado associado. DataFrames são construídos sobre o RDD, que é a abstração de dados mais fundamental do Spark. Embora compartilhem características com bancos de dados relacionais, DataFrames possuem técnicas avançadas de otimização, tornando o processamento mais eficiente.
Ilustrando com um meme o que é seria um RDD

Referências
Spark Fundamentals - Medium
Different ways to define the structure of DataFrame using Spark StructType - ProjectPro
What are Resilient Distributed Datasets (RDD)? - phoenixNAP