Adaptive Query Execution
O Adaptive Query Execution (AQE) é uma característica inovadora do Apache Spark que tem como principal objetivo otimizar consultas em tempo real. Ele opera monitorando e coletando estatísticas sobre os dados e o ambiente durante a execução. Baseando-se nessas informações, o AQE implementa otimizações para melhorar a eficiência da consulta. Introduzido na versão 3.0 do Spark, o AQE apresenta várias capacidades, sendo uma das mais notáveis a "Coalescência Dinâmica de Partições para Shuffle" (Dynamically Coalescing Shuffle Partitions).
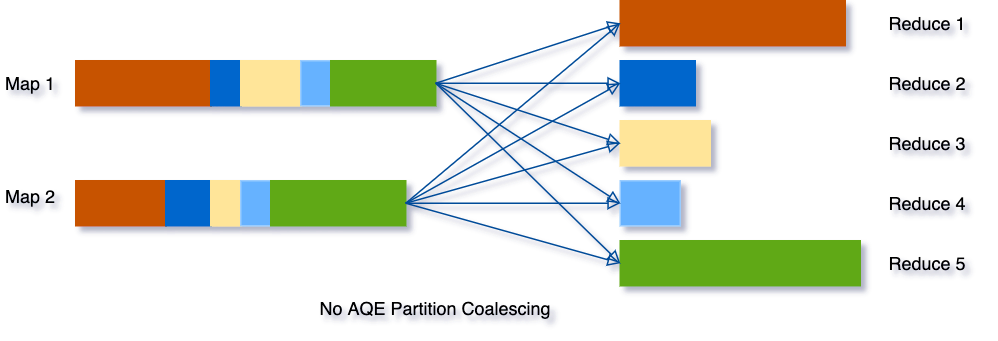
Coalescência Dinâmica de Partições para Shuffle:
A operação de "shuffle" é uma das mais custosas no Spark, principalmente devido à necessidade de redistribuição de dados entre partições. O AQE aborda esse desafio otimizando o shuffle. Ele agrupa dinamicamente partições que são menores e geograficamente próximas, minimizando o volume de dados trocados. Esta otimização é ilustrada por meio de um diagrama visual, mostrando a estrutura das partições antes e depois do processo de coalescência.

Troca Dinâmica de “Estratégias de Join”
Ao executar uma operação de "join" no Spark, diferentes estratégias são aplicadas em segundo plano para otimizar a operação. Entre as estratégias mais comuns, destacam-se o "Broadcast Hash Join" e o "Shuffle Sort Merge Join". O "Broadcast Hash Join" é geralmente considerado mais eficiente e é frequentemente a primeira escolha, especialmente quando um dos datasets é significativamente menor que o outro. No entanto, há situações em que o "Shuffle Sort Merge Join" pode ser mais adequado.
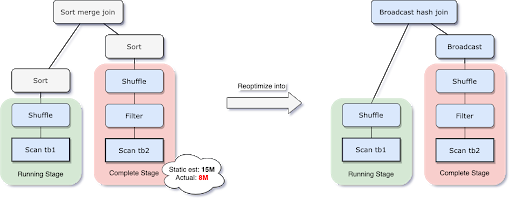
Dynamically Switching Join Strategies:
Com o recurso Adaptive Query Execution (AQE), o Spark tem a capacidade de alternar dinamicamente entre essas estratégias de "join" com base nas estatísticas dos dados em tempo real. Assim, se inicialmente o Spark escolhe uma estratégia, mas ao coletar estatísticas durante a execução percebe que outra estratégia seria mais eficiente, ele pode mudar para essa estratégia. Isso proporciona uma execução mais otimizada, adaptando-se dinamicamente às características dos dados e às necessidades da operação de "join".
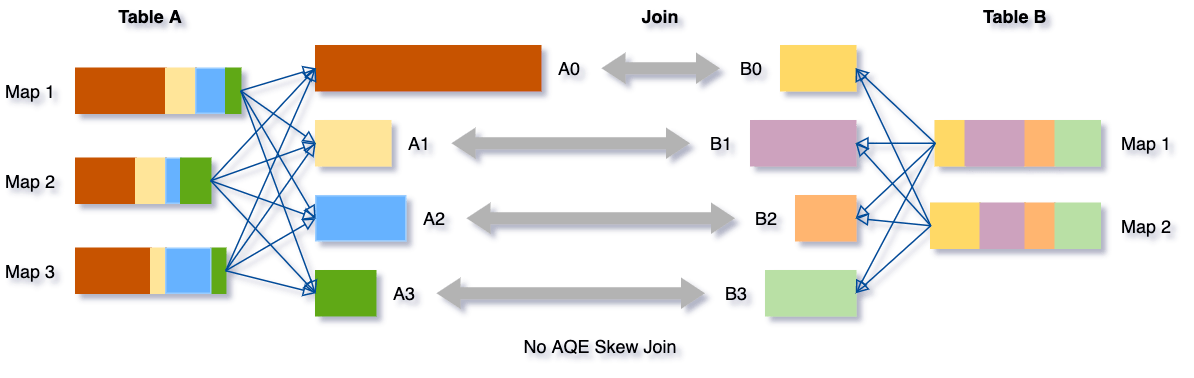
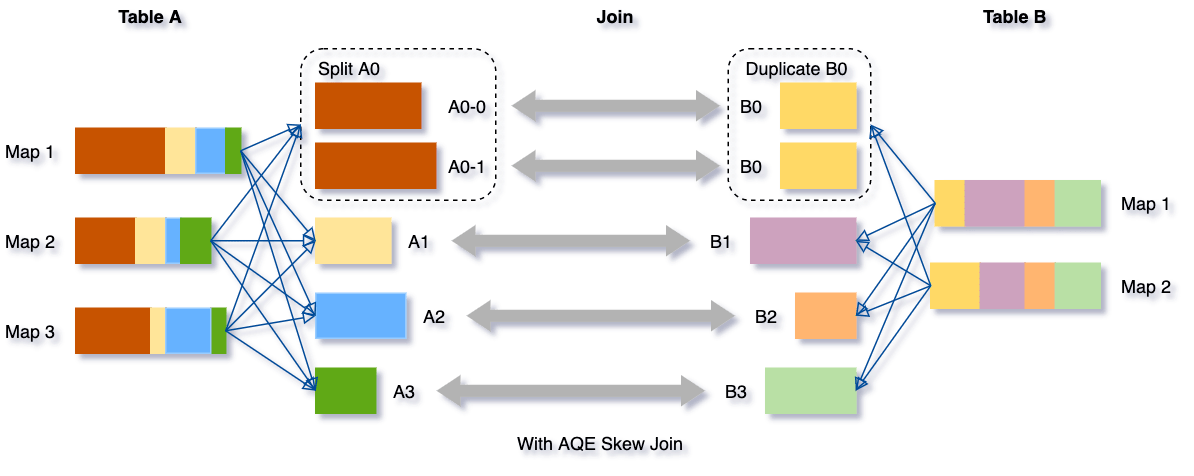
Dynamically Optimizing Skew Joins
"Joins inclinados" ou "Skew Joins" referem-se ao cenário onde, durante uma operação de "join", uma ou mais partições são significativamente maiores do que as outras, levando a desequilíbrios na carga de trabalho distribuída. Esses desequilíbrios podem ser problemáticos, pois partições maiores levam mais tempo para serem processadas, tornando-as pontos de estrangulamento que atrasam a execução completa de jobs.
Com o Adaptive Query Execution (AQE) do Spark, é possível abordar dinamicamente esse problema. Quando o Spark detecta que uma partição é significativamente maior e pode causar um "join inclinado", ele automaticamente quebra a partição grande em partições menores, a fim de distribuir a carga de trabalho de forma mais uniforme entre os executores. Isso aumenta o paralelismo e melhora a eficiência geral da operação. Para visualizar isso, imagine um gráfico ou uma ilustração que mostre um "join" com a partição A0, significativamente maior que a partição B0. Após a otimização com AQE, A0 é quebrado em várias partições menores, cada uma se
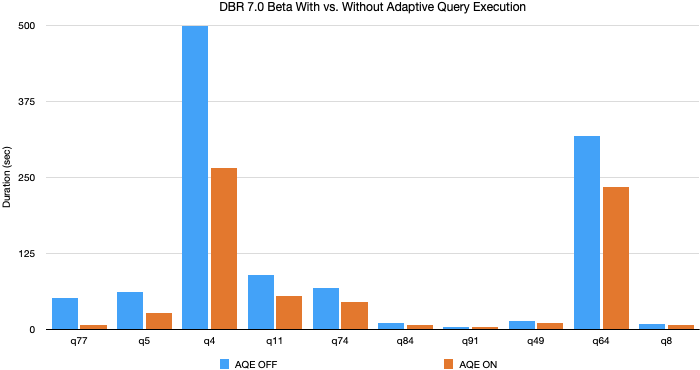
Ganhos de desempenho do TPC-DS do AQE
Para ativar no Spark
O Adaptive Query Execution (AQE) é uma poderosa funcionalidade do Spark 3.0 que, quando ativada, pode oferecer otimizações significativas em tempo real durante a execução das consultas. Para habilitar o AQE, é necessário ajustar uma configuração específica no Spark.
Como Ativar:
Como Ativar:
Configure o parâmetro spark.sql.adaptive.enabled para true. Vale ressaltar que o valor padrão dessa configuração no Spark 3.0 é false.
Referências:
Adaptive Query Execution: Speeding Up Spark SQL at Runtime - Databricks
AQE Demo - Databricks
Spark 3.0 Feature: Dynamic Partition Pruning (DPP) to Avoid Scanning Irrelevant Data - Medium
Spark 3.0: Adaptive Query Execution & Dynamic Partition Pruning