Arquitetura
Vamos abordar aqui a arquitetura tendo como perspectiva dois níveis de paralelização são eles o de dados e o de tarefas. Vamos iniciar com o de dados, pois ele trata sobre a infraestrutura.
O primeiro ponto que temos que trazer é que o Spark é um contêiner Java Virtual Machine (JVM) = O. Eu tive essa reação quando descobri isso.
Java Virtual Machine (JVM):
A JVM é uma máquina virtual que permite que um computador execute aplicações Java. Ela converte o bytecode Java, que é independente de plataforma, em instruções específicas da máquina para execução. Isso permite que o código Java seja escrito uma vez e executado em qualquer dispositivo ou sistema operacional que tenha uma JVM.
Containers:
Containers são uma tecnologia de virtualização que permite empacotar uma aplicação e todas as suas dependências, bibliotecas e configurações em um único pacote. Ao contrário das máquinas virtuais tradicionais, os containers compartilham o mesmo sistema operacional do host, mas têm espaços de execução isolados. Isso os torna leves e rápidos.
Outra informação relevante sobre é que a paralelização de dados envolve dividir os dados em múltiplas partições, permitindo que cada uma seja processada de forma independente em nós distintos de um cluster. No Spark, essa abordagem possibilita a execução simultânea de operações em diversas partições, otimizando consideravelmente a velocidade de processamento.
Nível de paralelização de dados
Dado essa contextualização, podemos introduzir a infraestrutura do spark. Abaixo temos algumas imagens de como essa arquitetura é representada:
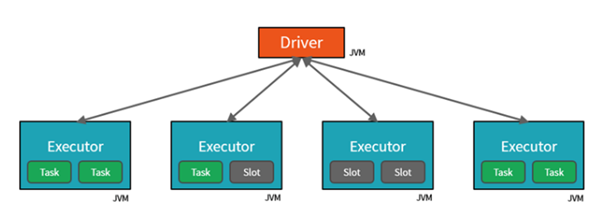
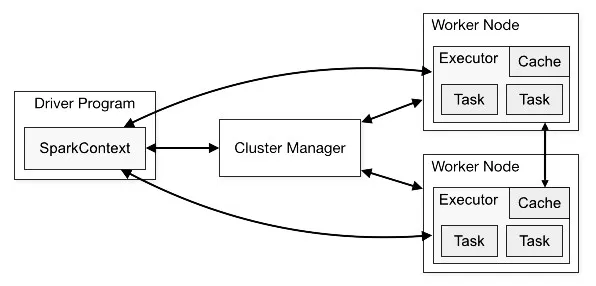
Vamos explorar os seguintes itens dos desenhos acima: sparkSession, Spark Driver, Cluster Manager, Executer, Slot
Spark Session
A Spark Session funciona como o principal ponto de entrada para interagir com as funcionalidades do Apache Spark. Oferecendo uma interface global para realizar tarefas rotineiras, facilita a interação com os dados e assegura uma abordagem uniforme ao seu processamento. Por meio da Spark Session, os usuários podem executar SQL, Rspark, Pyspark e Scala em seus conjuntos de dados.
Spark Driver
Principais responsabilidades do Spark Driver:
Criação do Spark Session/Context.
Análise e otimização do plano de execução.
Segmentação em tarefas.
Distribuição do código para os executores.
Gerenciamento do DAG e da linhagem (Lineage).
Coordenação dos executores.
Coleta dos resultados.
Monitoramento e recuperação em caso de falhas.
Finalização e encerramento da aplicação.
Atua como o nó mestre no contexto de processamento distribuído.
Resumo: O Spark Driver atua como o coração da aplicação Spark, tomando conta de todo o processamento. Ele coordena a execução em um ambiente de cluster, otimiza o plano de execução e garante confiabilidade e tolerância a falhas durante o tratamento dos dados.
Cluster Manager
Principais responsabilidades do Cluster Manager:
Alocação de recursos.
Monitoramento dos recursos.
Resumo: O Cluster Manager do Spark desempenha uma função vital no gerenciamento de recursos e assegura a execução eficiente dos aplicativos Spark em um ambiente de cluster distribuído.
Curiosidade: O Spark suporta diversos gerenciadores de cluster, como seu próprio gerenciador Standalone, bem como Apache Mesos, Hadoop YARN e Kubernetes.
Workers/Executores
Principais atividades dos Workers/Executores:
Execução de tarefas.
Processamento paralelo.
Acesso a dados, seja em memória ou em disco.
Realização de transformações e ações.
Gerenciamento de partições.
Comunicação com o Spark Driver.
Resumo: O executor, também conhecido como worker, tem a crucial responsabilidade de conduzir o processamento distribuído real no Spark. Ele executa tarefas, processa dados em paralelo e mantém comunicação contínua com o Spark Driver. Essas ações garantem eficiência na execução e capacidade de recuperação diante de possíveis falhas no ambiente distribuído.
Slots
Um slot é a menor unidade de paralelismo em dados no Spark. O número de slots em um executor determina quantas tarefas podem ser realizadas simultaneamente. Por exemplo, se um executor possui 4 slots, ele pode processar até 4 tarefas ao mesmo tempo, desde que estas tarefas estejam prontas para serem executadas. Os slots são usados para regular a quantidade de recursos, tais como CPU e memória, que são destinados a cada tarefa.
Resumo: Os slots têm uma importância vital na determinação do paralelismo e no gerenciamento de recursos no Apache Spark. Eles asseguram que o Spark utilize de maneira eficaz os recursos disponíveis no cluster, possibilitando o processamento paralelo de tarefas e garantindo eficiência e escalabilidade em um ambiente distribuído.
Nível de paralelização das tarefas
Vamos discutir o nível de paralelização das tarefas. Mas, primeiramente, o que significa esse nível? A paralelização de tarefas refere-se à execução simultânea de diferentes operações em várias partições de dados. Quando aplicamos uma transformação ou ação em um RDD (Resilient Distributed Dataset) ou DataFrame no Spark, resulta-se em uma série de tarefas que são processadas em paralelo nos diferentes nós do cluster. Para aqueles familiarizados com o Airflow, a menção de DAG (Directed Acyclic Graph) trará lembranças, o que faz sentido, uma vez que neste contexto, o nível de paralelização é uma DAG, mas no Spark.
A seguir, apresentamos uma representação visual de como essa operação se desenrola. Em etapas futuras, vamos explorar esse aspecto visualmente dentro do Spark. No entanto, neste instante inicial, nosso foco será estritamente conceitual.
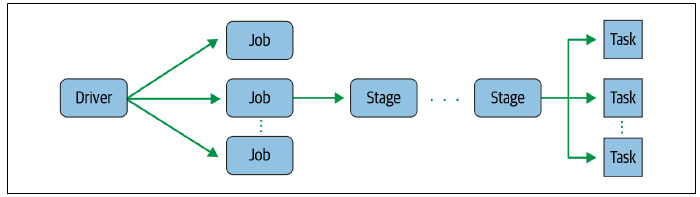
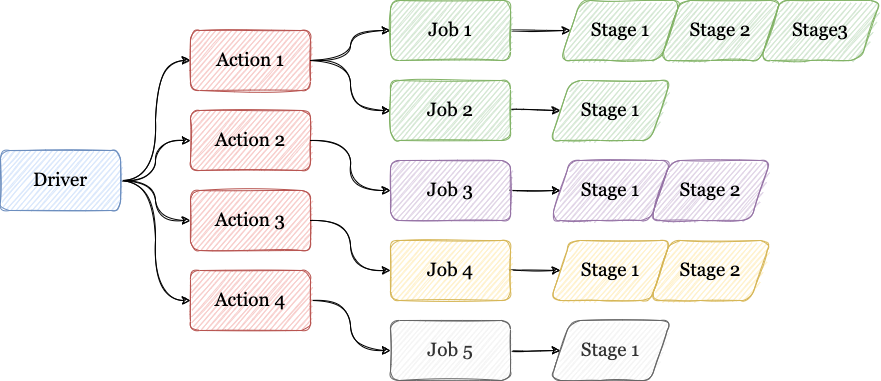
Job
Um job é uma unidade de trabalho ou um conjunto de tarefas que precisam ser realizadas no cluster para cumprir uma operação específica em um conjunto de dados. Quando executamos um aplicativo Spark, ele cria um plano de execução lógica para as transformações definidas pelo usuário em seus RDDs ou DataFrames. Este plano é representado como um DAG (Directed Acyclic Graph), mostrando a sequência de transformações aplicadas aos dados para obter o resultado almejado.
Resumo: No Spark, um job é uma unidade de trabalho que envolve transformações realizadas em um conjunto de dados distribuído, buscando alcançar um determinado resultado.
Stage
No contexto do Apache Spark, um "stage" representa uma divisão lógica do plano de execução que abrange uma série de transformações. Estas transformações podem ser realizadas simultaneamente, sem a necessidade de transferir dados entre as partições. Quando ativamos um aplicativo Spark, ele constrói um plano de execução lógica, representado por um DAG (Directed Acyclic Graph), com base nas transformações determinadas pelo usuário em seus RDDs. Este plano lógico é então fragmentado em vários "stages", e cada "stage" compreende um conjunto de transformações (ou tasks) que são processadas de forma paralela.
Resumo: No Spark, um "stage" é uma divisão lógica do plano de execução e simboliza um conjunto de transformações processadas simultaneamente.
Task
Uma "task", no Spark, é a menor unidade de execução e representa uma operação específica feita em uma partição de dados. As tasks são a unidade básica de trabalho no Spark. Elas são enviadas aos executores do cluster para processamento paralelo. Mais especificamente, uma task é destinada a um slot específico do executor.
Resumo: No Spark, uma "task" é a menor unidade de trabalho e denota uma operação específica realizada em uma partição de dados.
Conclusão
Como se inter-relacionam o nível de paralelização de dados e o nível de tarefas? O menor componente no nível de dados é o slot do executor. Este recebe do driver tasks (trechos de código) que são de sua responsabilidade executar em seu slot. No slot, dispomos de recursos computacionais, tais como CPU e memória RAM. Para finalizar, para que o código seja processado, precisamos de uma partição do nosso RDD juntamente com uma ação.
Referências
Getting Started with Apache Spark - Databricks
What is Apache Spark Driver? - SparkByExamples
Spark Basics: Application, Driver, Executor, Job, Stage and Task
Walkthrough - Kontext
Understanding Spark Application Concepts - Knoldus Blog
Spark Architecture 101 - Concepts & Application - DevGenius Blog
What Are Spark Applications? - Databricks
Spark: Jobs, Stages and Tasks - Medium by Thisun
Série Spark e Databricks - Parte 1: Arquitetura e Componentes do Apache